Modules
Module 2: System Architecture and Project Setup
Welcome to the second module of our GitHub RAG Project! Now that we've laid the groundwork with key AI concepts, it's time to dive into the nuts and bolts of our system. In this module, we'll explore the overall architecture of our application and set up the foundation for our development environment.
By the end of this module, you'll have a clear understanding of how all the pieces of our GitHub RAG system fit together, and you'll be ready to start building!
1. Project Overview
Before we delve into the technical details, let's take a moment to recap the goals of our GitHub RAG application:
- Allow users to search through their starred GitHub repositories more effectively
- Provide intelligent, context-aware responses to queries about repository content
- Offer real-time updates on the indexing and query process
To achieve these goals, we're building a system that combines modern web technologies, AI capabilities, and efficient data storage. Let's break down the key components:
2. Flow
Here's a step-by-step breakdown of how the application works:
- User Authentication: The user signs in with GitHub OAuth.
- User Identification: We obtain the GitHub username/user ID from the OAuth process.
- Repository Fetching: We make an API call to fetch all starred repositories for that user.
- README Retrieval: For each repository, we fetch the README file to understand what the repo is about.
- Ingest Preparation: We prepare the README content for the ingest algorithm.
- Ingest Algorithm:
- The algorithm chunks the text into manageable pieces.
- It generates embeddings for each chunk.
- These embeddings are stored in a PostgreSQL vector database.
- Metadata Storage: Along with the embeddings, we store GitHub metadata like repository URL and name.
- Real-time Updates: Throughout the process, we maintain a real-time connection to the client, updating them on the current step (e.g., fetching repos, ingesting data).
- User Interaction: Once ingestion is complete, the user can chat and ask questions about their starred repos, such as "Which repos contain OpenAI interactions?"
3. System Architecture
The GitHub RAG project is designed with a clear separation of concerns between the frontend and backend, leveraging the strengths of both Next.js and FastAPI. This architecture allows for efficient handling of AI-related tasks while providing a smooth user experience.
3.1 Frontend (Next.js 14)
Our frontend is built with Next.js 14, leveraging the latest features of this powerful React framework. Key responsibilities include:
- Authenticating users with GitHub OAuth
- Providing a user-friendly interface for interacting with the FastAPI backend
- Displaying progress and results of various operations
- Communicating with the backend via RESTful API calls and WebSocket connections
While Next.js 14 is a full-stack framework capable of handling backend logic, we've chosen to separate concerns to leverage Python-based AI libraries more effectively.
3.2 Backend (FastAPI)
The backend of our application is powered by FastAPI, a modern, high-performance Python web framework. It serves as a controller/orchestrator and handles:
- API endpoints for repository fetching, ingestion, and query processing
- Integration with external services (GitHub API, LLM Gateway)
- WebSocket server for real-time updates
- Orchestration of various tasks like ingestion and chatting
- Core logic of the RAG system, including embedding generation and retrieval
The backend does not handle user authentication, as this is managed by the frontend through GitHub OAuth.
3.3 Real-time Communication
To provide a seamless user experience, we've implemented WebSocket connections between our backend and frontend. This allows us to:
- Send real-time updates on the indexing process of repositories
- Provide instant feedback during the query and response generation process
3.4 External Services
Our application integrates with several external services:
-
GitHub API: For fetching user repositories and README contents. This allows us to work with up-to-date information directly from the user's GitHub account.
-
LLM Gateway: This abstraction layer for LLM interactions provides several key benefits:
- Unified interface: Enables interaction with multiple different LLMs using the same logic and API calls.
- Flexibility: Allows easy switching between different LLM providers or models without changing application code.
- Optimized performance: Can implement caching, rate limiting, and other optimizations centrally.
- Cost management: Facilitates better tracking and control of API usage across different LLMs.
- Version control: Enables seamless updates to newer LLM versions without disrupting the main application.
- Enhanced security: Centralizes API key management and can implement additional security measures.
The LLM Gateway is used to generate embeddings and power our RAG system, ensuring consistent and efficient LLM interactions throughout the application.
-
Vector Database: For efficient storage and retrieval of embeddings. This specialized database allows for fast similarity searches, which is crucial for the performance of our RAG system.
-
Helicone: For comprehensive monitoring and analytics of LLM usage. This provides valuable insights into performance, costs, and usage patterns, helping to optimize the application over time.
By leveraging these external services, our application can focus on its core functionality while relying on specialized tools for specific tasks, resulting in a more robust, scalable, and maintainable system.
4. Retrieval and Ingest Pase in details
As we wrap up this module, let's take a closer look at the crucial ingest and retrieval phases of our GitHub RAG system, which form the backbone of how we collect, process, and utilize data from repositories.
4.1 Ingest Phase
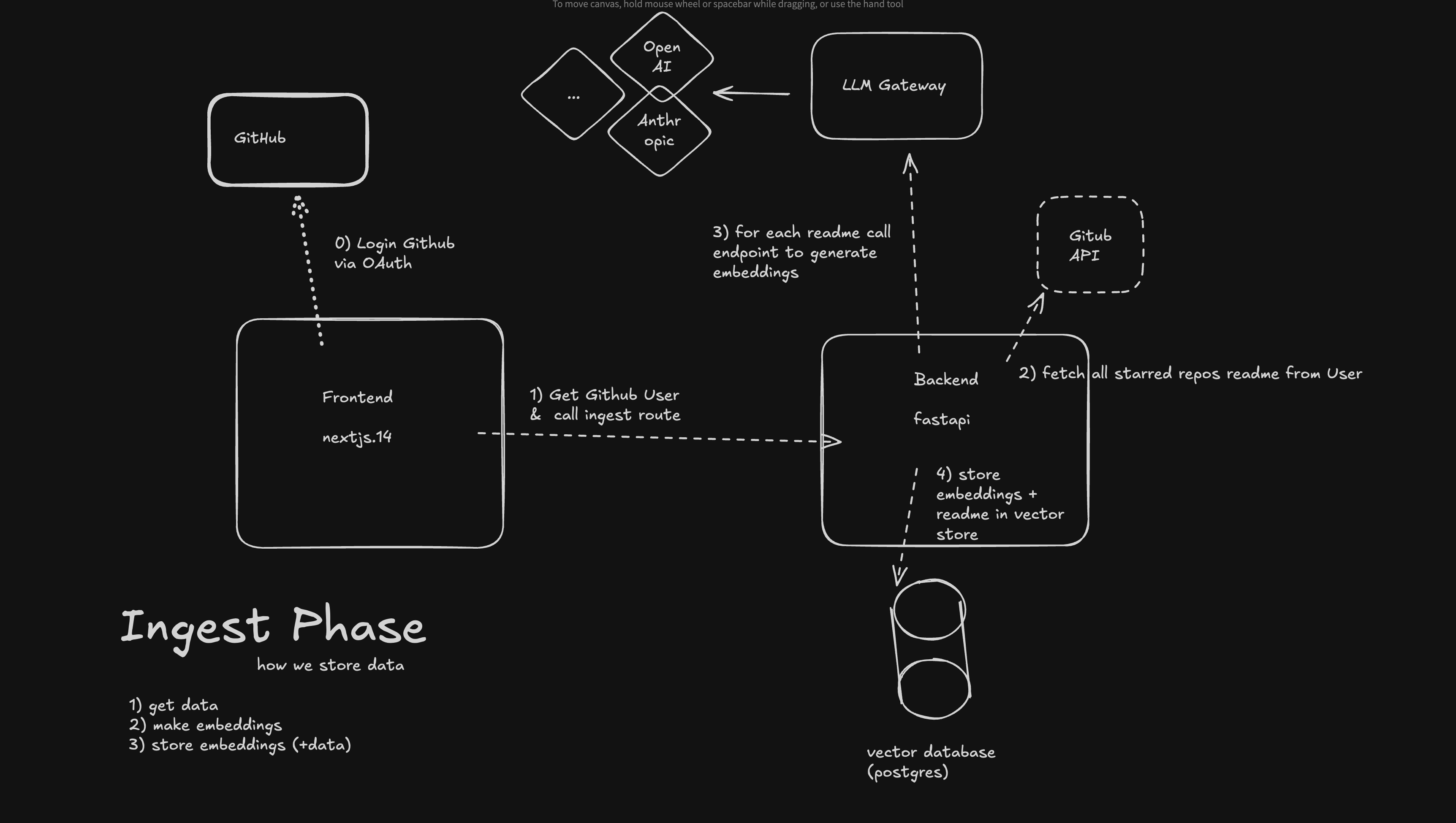
The ingest phase is responsible for collecting and storing data from GitHub repositories. Here's how it works:
- Frontend calls the
/ingestendpoint on the backend (FastAPI). - Backend fetches all starred repos and their READMEs from the GitHub API.
- For each README, the backend generates embeddings using an LLM Gateway.
- Embeddings and README content are stored in a vector database (Postgres with pgvector).
4.2 Retrieval Phase
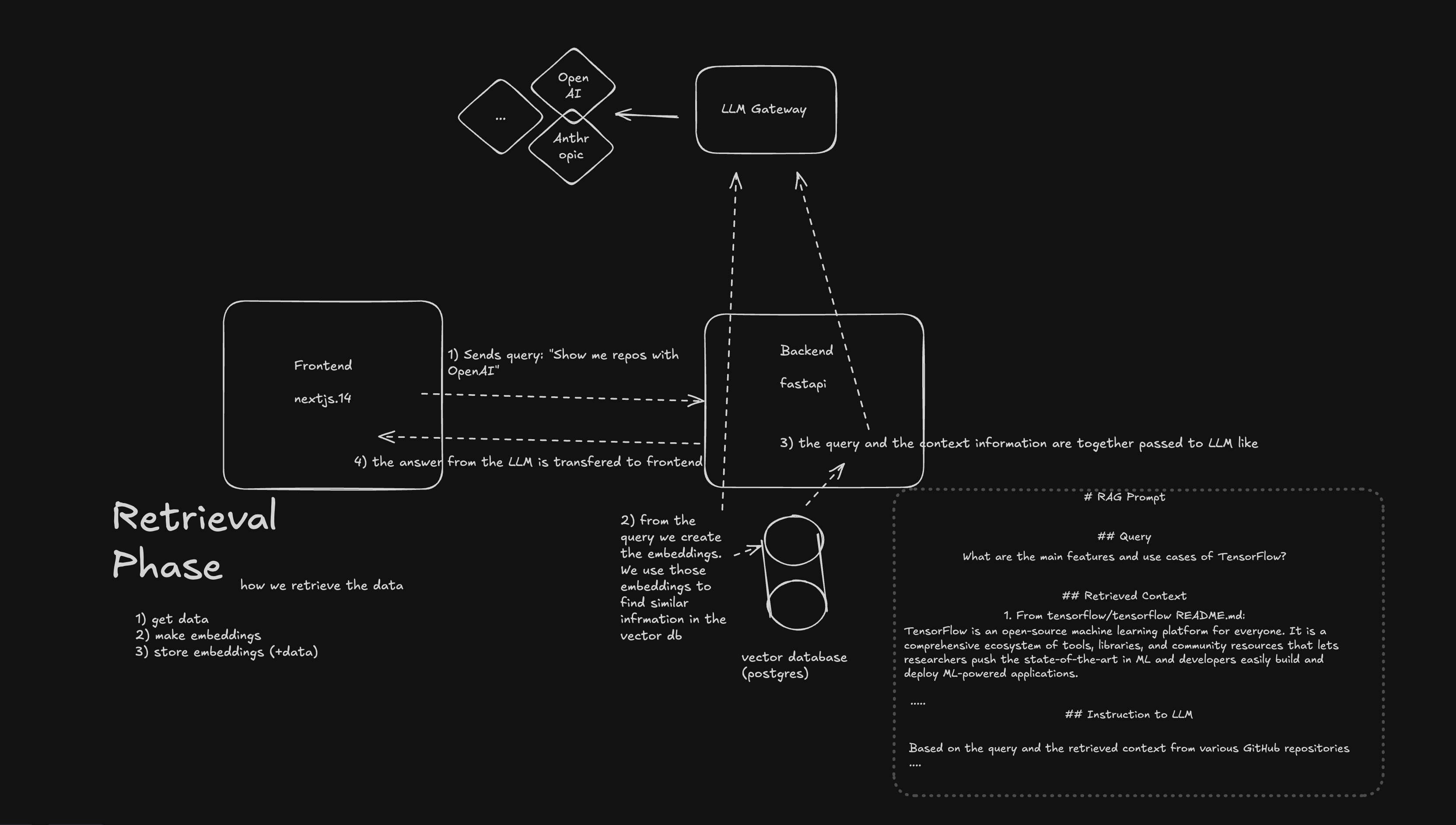
The retrieval phase occurs when a user interacts with the chat interface. Here's the process:
- User sends a query through the frontend (e.g., "Show me repos with OpenAI").
- Frontend sends the query to the
/chatendpoint on the backend. - Backend creates an embedding for the query.
- Similar information is retrieved from the vector database using the query embedding.
- Retrieved context and the original query are sent to the LLM Gateway.
- LLM generates a response based on the query and context.
- Response is sent back to the frontend and displayed to the user.
Key Learning Points:
- The GitHub RAG system combines Next.js frontend with FastAPI backend for efficient AI task handling
- The LLM Gateway provides a unified interface for interacting with multiple language models
- The ingest phase in RAG systems involves collecting, processing, and storing relevant data for future retrieval
- The retrieval phase in RAG systems focuses on finding relevant information based on user queries and generating informed responses. We enrich the query to the LLM with the context information (in our case similar github repos) we found from the vector store.
- The system architecture allows for separation of concerns and scalability
- Vector similarity search in PostgreSQL (pgvector) is crucial for efficient information retrieval